개요
Agora 프로젝트를 서버 배포에 성공하고, 서비스가 얼마나 많은 사용자를 감당할 수 있을지 알고 싶어 졌습니다. 이를 위해 성능 테스트를 진행해보았습니다. 이번 포스팅 시리즈는 성능 테스트를 진행하면서 겪은 성능적인 이슈와 이를 분석하고 해결해나가면서 겪은 경험을 공유하고자 시작하였습니다.
먼저 성능 테스트는 어떤 작업일까요? 지금부터 성능 테스트에 대해서 알아보겠습니다.
성능 테스트는 왜 해야 할까요?
성능 테스트는 말 그대로 서비스의 성능적인 부분을 측정하기 위해 실행되는 작업입니다. 애플리케이션의 성능을 측정한다는 것은 점진적인 부하를 가하는 과정 속에서 더 이상 처리량이 증가하지 않을 때, 그 수치를 측정하고 해석하는 것을 의미합니다.
그렇다면 이러한 행위는 왜 하는 걸까요?
성능 테스트의 목적은 첫 번째로 현재 애플리케이션이 최대 몇 명의 사용자를 수용할 수 있는지 측정하고, 그 결과가 최초 목표한 성능에 부합하는지 알아내기 위함입니다.
두 번째는 만약 목표 성능에 부합하지 않는다면 어떤 지점에서 병목이 발생하고, 이를 해결하기 위해 무엇을 해야 하는지 분석하여 개선함으로써 최종적으로 서비스가 중단되는 상황 없이 제공될 수 있도록 가용성을 높이는 것입니다.
이러한 성능 테스트의 목적을 달성하기 위해서 서비스가 빠른지 느린지에 대한 명확한 기준이 필요합니다.
그렇다면 서비스의 성능은 어떤 수치를 기준으로 알 수 있을까요?
지금부터 성능 테스트의 기준이 되는 성능 지표에 대해 알아보겠습니다.
서비스가 빠른지 느린지 어떻게 알 수 있을까?
서비스의 속도를 결정하는 기준은 Throughput과 Latency를 보면 알 수 있습니다.
Throughput? Latency? 각각의 성능 지표가 어떤 것이길래 서비스의 성능을 파악할 수 있을까요?
Throughput부터 차례대로 알아보겠습니다.
Throughput이란 시간당 처리량을 의미합니다. TPS(Transaction Per Second), RPS(Request Per Second) 등으로도 불리며, '1초에 처리하는 단위 작업의 수' 혹은 '1초에 처리하는 HTTP 요청 수' 등으로 해석할 수 있습니다.
즉, 1초에 최대한 많은 작업을 처리할 수 있는 서비스가 성능 측면에서 좋은 서비스라고 볼 수 있습니다.
예를 들어, A 서비스는 1초에 1000개의 작업을 처리하고 B 서비스는 1초에 2000개의 작업을 처리할 수 있는 능력을 가졌다면 B 서비스가 동일 시간 내에 더 많은 작업을 할 수 있으므로 성능면에서 더 좋다고 볼 수 있겠죠?
이렇듯 Throughput을 보면 내 서비스의 작업 처리 능력을 알 수 있으며, 이는 서비스 성능의 지표가 될 수 있습니다.
다음은 Latency입니다.
서비스의 성능을 말할 때, Latency는 서버가 클라이언트로부터 요청을 받아서 응답을 보내주기까지 걸리는 시간을 의미합니다. 쉽게 말해서 Latency는 서비스가 작업을 얼마나 빠르게 처리할 수 있는지를 나타내는 성능 지표로 볼 수 있습니다. 영어 그대로 직역해보자면 서버가 클라이언트의 요청을 처리하는데 발생하는 지연시간으로도 생각해볼 수 있습니다.
예를 들어, A 서비스의 웹 서버가 WAS로부터 요청을 응답을 보내는데 걸리는 시간이 100㎳이고, B 서비스의 WAS가 동일 작업을 처리하는데 50㎳가 걸렸다면 B 서비스가 작업을 더 빨리 처리할 수 있음을 알 수 있고, 이에 따라 성능면에서 더 좋다고 볼 수 있습니다.
지금까지 서비스의 성능을 파악할 수 있는 기준을 알아보았습니다. 그렇다면 여러 개의 시스템으로 구성된 웹 서비스에서 성능을 어떻게 해석해야 하고, 개선해야 하는지 자세히 알아보도록 하겠습니다.
서비스 성능에 대한 기준이 생겼으니, 기준에 따라 해석하고 개선해볼까요?
위에서 잠시 언급했지만 웹 서비스는 여러 시스템으로 구성되어 있습니다. 지금은 쉽게 설명하기 위해서 웹 서버 - WAS - DB로 구성된 서비스를 예로 살펴보겠습니다. 아래 그림은 해당 서비스의 구성과 각 하위 시스템들의 성능을 표시하였습니다. 설명을 위해 예를 든 것이니 혹시나 모든 성능이 저런 비율로 측정된다고 오해 없으시길 바라겠습니다.
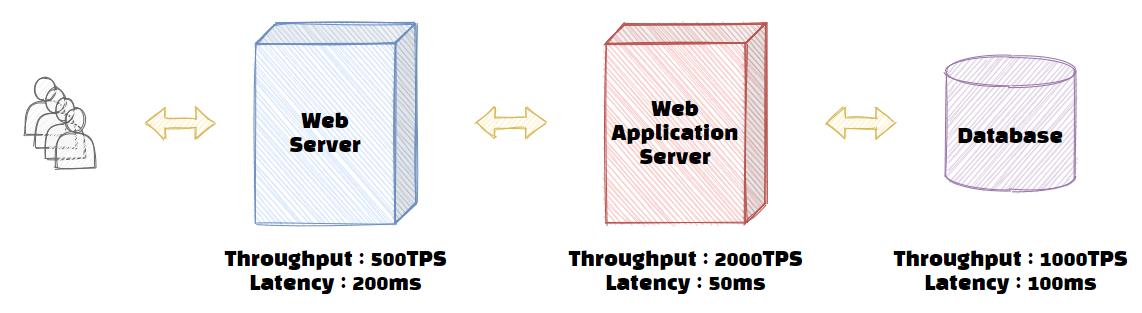
| Web Server | Web Application Server | Database | |
| Throughput | 500TPS | 2000TPS | 1000TPS |
| Latency | 200ms | 50ms | 100ms |
우선 그림을 보고 잠시 생각해봅시다! 그림이 잘 안 보이시면 표를 참고해주시길 바랍니다. 전체 서비스의 Throughput은 얼마나 될까요?

정답은 500 TPS입니다.
모든 처리량을 더하면 3500 TPS 아닌가? 아니면 가장 높은 Throughput인 2000 TPS가 처리량이 되는 게 아닌가?라고 생각하셨을 수 있을 것이라고 생각됩니다.(물론 제 얘기입니다...ㅎ)
성능에 대한 비유는 흔히 고속도로 정체 상황을 비유합니다. 하나의 작업을 차 한 대로 가정하고, 500 TPS는 Web 서버라는 고속도로를 1시간당 500대의 차가 통과한다고 가정하겠습니다.
이러한 상황에서 만약에 2000대의 차량이 해당 도로를 통과하면 어떤 일이 벌어질까요?
총 TPS의 합이 3500 TPS이니까 모든 도로가 원활하게 차를 수용할 수 있을까요?
역시 불가능합니다. Web 서버에서 차들은 정체되고, WAS와 데이터베이스는 Web 서버를 통과한 차들만 수용할 수 있으므로 아무리 시간당 1000대, 2000대를 통과시킬 수 있는 수용력이 있어도 결국에는 시간당 500대만 통과하게 됩니다.
현재 상황을 웹 서비스로 다시 돌아와 보면 이러한 경우, 웹 서버에서 병목이 발생했다고 볼 수 있습니다.
그렇다면 여기서 DB나 WAS 성능을 아래와 같이 개선한다고 해서 전체 서비스의 성능이 올라갈까요?
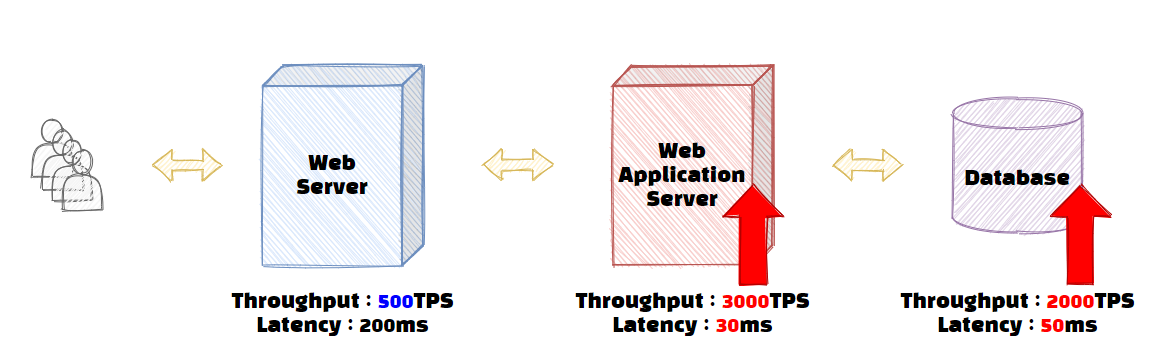
| Web Server | Web Application Server | Database | |
| Throughput | 500TPS | 3000TPS | 2000TPS |
| Latency | 200ms | 30ms | 50ms |
보시다시피 Web 서버의 Throughput은 500 TPS로 동일하기 때문에 해당 서비스는 여전히 초당 500개의 트랜잭션만 통과할 수 있습니다. 이러한 병목 현상과 같이 서비스의 성능 중 가장 큰 영향을 미치는 부분을 Critical Path라고 합니다. 서비스의 전체 성능을 높이기 위해서는 병목을 Critical Path를 찾아야 하고, 여기에 해당하는 Throughput이 증가해야만 해결할 수 있습니다.
다시 돌아와서 데이터베이스와 WAS는 그대로 두고 Web 서버의 성능을 개선해볼까요?

| Web Server | Web Application Server | Database | |
| Throughput | 2000TPS | 2000TPS | 1000TPS |
| Latency | 50ms | 50ms | 100ms |
그림을 보면 Web서버의 Throughput이 개선되자 Web서버와 WAS에서는 2000개의 트랜잭션을 처리할 수 있게 되었습니다. 하지만 데이터베이스에서는 초당 2000개의 처리 작업을 수행할 수 없으니, 서비스 전체의 Throughput은 데이터베이스의 Throughput인 1000 TPS로 변경되었습니다. 그래도 이전 500 TPS에서 1000 TPS로 Throughput이 개선되었으니 해당 서비스의 성능은 2배 빨라졌다고 할 수 있습니다.
또한 병목이 Web서버에서 데이터베이스로 옮겨갔죠? 이와 같이 기존 구간의 성능 개선을 하게 되면 Critical Path는 이동하게 되고, 우리는 이러한 병목 구간을 Critical Path를 지속적으로 해결하면서 전체 서비스의 성능을 올려야만 합니다.
종합해보면 우리가 서비스의 Throughput이라고 말하는 것은 서비스의 하위 시스템들 중 가장 낮은 처리량을 의미합니다. 또한 Throughput 관점에서 성능을 개선한다는 의미는 Critical Path를 찾아서 이를 개선하는 것이라고 할 수 있습니다.
다음으로 서비스의 Latency는 얼마일까요?
| Web Server | Web Application Server | Database | |
| Throughput | 500TPS | 2000TPS | 1000TPS |
| Latency | 200ms | 50ms | 100ms |
서비스의 Latency는 대기시간을 포함한 각 하위 시스템 Latency의 총합입니다. [그림 1]을 다시 참고하면 현재 서비스의 Latency는 '350ms + 대기시간'으로 해석할 수 있습니다.
Latency를 개선하기 위해서 고려할 요소들은 굉장히 많습니다. 기본적으로 하드웨어의 처리 성능, 애플리케이션 로직, 쿼리 인덱스 등 다양한 원인으로 작업의 Latency가 발생할 수 있습니다. 더 나아가 Throughput이 한계점에 도달하면 대기시간 또한 길어지므로 Latency 발생의 원인이 될 수 있습니다.
Throughput을 분석할 때와 달리 Latency의 경우, 하나의 하위 시스템 Latency가 줄어들면 전체 서비스의 Latency도 줄어들게 되므로 병목 구간을 찾기보다 가장 Latency가 큰 하위 시스템을 개선하는 것이 서비스의 Latency를 큰 폭으로 줄일 수 있는 방법입니다.
| Web Server | Web Application Server | Database | |
| Throughput | 500TPS | 3000TPS | 2000TPS |
| Latency | 200ms | 30ms | 50ms |
[그림 2]의 경우, 병목 구간이 그대로 이기 때문에 Throughput은 개선 전과 동일했지만 Latency는 WAS 20ms + 데이터베이스 50ms = 70ms 줄어들어서 전체 서비스의 대기시간을 제외한 Latency가 '350ms'에서 '280ms'로 줄어드는 것을 확인할 수 있습니다. 이렇듯 서비스 Latency 개선의 경우, 병목 지점과 관계없이 각 하위 시스템들의 Latency 개선이 전부 영향을 줄 수 있음을 알 수 있습니다.
| Web Server | Web Application Server | Database | |
| Throughput | 2000TPS | 2000TPS | 1000TPS |
| Latency | 50ms | 50ms | 100ms |
물론 [그림 3]처럼 Throughput을 개선하면 대기시간이 줄어들어 Latency를 줄일 수 있기 때문에 Throughput을 개선하는 것이 Latency 개선에도 영향을 줄 수 있습니다.
결론
- 성능 테스트는 서비스가 목표하는 최대 사용자 수에 도달하기 위해 현재 성능을 파악하고, 개선하는 작업입니다.
- 서비스의 성능을 알 수 있는 지표는 Throughput과 Latency가 있습니다.
- 전체 서비스의 성능을 개선하기 위해서는 하위 시스템의
병목 구간을Critical Path를 찾아 개선하여 Throughput이 증가해야만 하고, 각 하위 시스템의 Latency를 줄여서 전체 서비스의 Latency를 줄여야만 합니다.
참고
- 아마존 웹 서비스 부하 테스트 입문, (나카가와 타루하치, 모리시타 켄 지음, 박상욱 옮김), Jpub 출판
프로젝트 참고
- Social Network Service AGORA, https://github.com/f-lab-edu/sns-project
f-lab-edu/sns-agora
소셜 네트워크 서비스 AGORA입니다. Contribute to f-lab-edu/sns-agora development by creating an account on GitHub.
github.com
다음 포스팅에는
다음 포스팅에는 성능 테스트를 위해 부하를 줄 도구에 대해 알아보고, AGORA 서비스의 현재 성능 상태를 측정해보도록 하겠습니다!
'Performance' 카테고리의 다른 글
| 내가 만든 서비스는 얼마나 많은 사용자가 이용할 수 있을까? - 3편(DB Connection Pool) (13) | 2021.01.14 |
|---|---|
| 내가 만든 서비스는 얼마나 많은 사용자가 이용할 수 있을까? - 2편(nGrinder를 활용한 성능테스트) (6) | 2020.12.27 |

